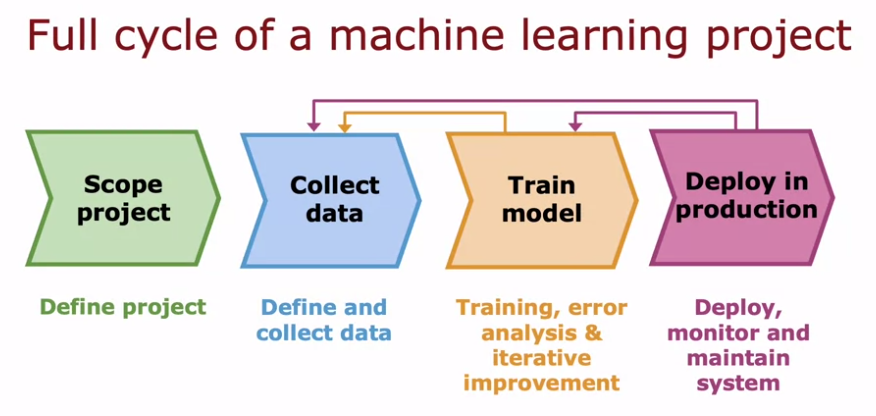
ML Development Process
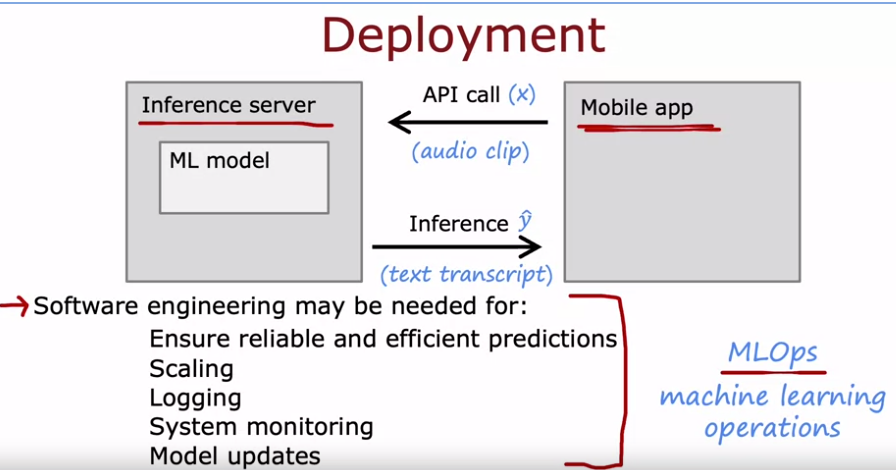
Development Operations
Intro
building an email spam classifier This application is an example of text classification because you’re taking a text document that is an email and trying to classify it as either spam or non-spam.
-
Data Acquisition Honeypot Projects: Imagine planting bait for digital pirates! These projects create vast networks of fake email addresses specifically designed to attract spammers. Every email received becomes a labeled data point, enriching the training pool for spam filters.
- Feature Engineering:
- Email Routing: Just like following breadcrumbs, analyzing the email’s path can be revealing. The sequence of servers it traversed, the geographical hops, and even unexpected detours can unveil suspicious patterns often characteristic of spam campaigns.
- Dissecting the Body: This is where linguistic finesse comes in. Algorithms can identify telltale signs like excessive exclamation points, suspicious URLs, or manipulative language often used in phishing attempts. Advanced techniques like stemming (discount/discounted) and n-gram analysis (identifying common word sequences) further refine the detection process.
-
Beyond Binary: While the core task is classifying spam versus non-spam, more nuanced labels can add another layer of sophistication. Categorizing spam into further types like phishing, scams, or malware alerts can help users prioritize potential threats.
- The Evolving Arms Race: Spammers, like any resourceful villain, adapt. This necessitates continuous improvement in classification techniques. Research in areas like natural language processing and anomaly detection helps stay ahead of the curve, ensuring your inbox remains a safe haven.
Error analysis
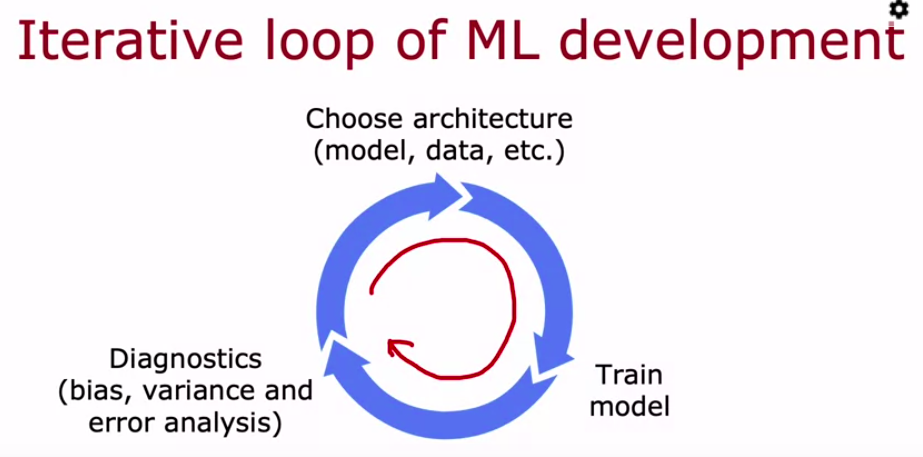
After Bias,Variance analysis
- Manual inspection of misclassified examples: By hand-picking and analyzing cases where your algorithm goes wrong, you gain valuable insights into its weaknesses.
- Grouping errors by common traits: Categorize misclassified examples based on shared features like pharmaceutical spam, deliberate misspellings, or phishing attempts.
- Quantifying impact: Count how many errors fall into each category to understand their relative influence on overall performance.
- Prioritizing improvements: Focus on tackling the most impactful error categories, like pharmaceutical spam in this example, rather than spending time on less significant areas like deliberate misspellings.
- Limitations: This method works best for tasks we intuitively grasp, like spam detection. Analyzing problems beyond human comprehension, like ad click prediction, becomes more challenging.
Insights:
Both techniques offer valuable feedback for optimizing your learning algorithm. Use error analysis to identify critical problem areas, and leverage bias-variance analysis to determine the most effective data collection strategy for addressing those areas. if error analysis has indicated that there are certain subsets of the data that the algorithm is doing particularly poorly on. And that you want to improve performance on, then getting more data of just the types where you wanted to do better.
Adding data
Add more data of the types where error analysis has indicated it might help.
There’s another technique that’s widely used especially for images and audio data that can increase your training set size significantly. This technique is called data augmentation.
Data augmentation
-
images: Given an image of A, you might decide to create a new training example by rotating the image a bit. Or by enlarging the image a bit or by shrinking a little bit or by changing the contrast of the image. And these are examples of distortions to the image that don’t change the fact that this is still the letter A And for some letters but not others you can also take the mirror image of the letter and it still looks like the letter A. But this only applies to some letters but these would be ways of taking a training example X, Y. And applying a distortion or transformation to the input X ,in order to come up with another example that has the same label. For a more advanced example of data augmentation. You can also take the letter A and place a grid on top of it. And by introducing random warping of this grid, you can take the letter A. And introduce warpings of the leather A to create a much richer library of examples of the letter A. And this process of distorting these examples then has turned one image of one example into here training examples that you can feed to the learning algorithm to hope it learn more robustly.
-
speech recognition: This idea of data augmentation also works for speech recognition. Let’s say for a voice search application, you have an original audio clip that sounds like this. » What is today’s weather. » One way you can apply data augmentation to speech data would be to take noisy background audio like this. For example, this is what the sound of a crowd sounds like.
if that’s representative of what you expect to hear in the test set, then this will be helpful ways to carry out data augmentation
Photo OCR
And one key step with the photo OCR task is to be able to look at the little image like this, and recognize the letter at the middle. So one way to create artificial data for this task is if you go to your computer’s text editor, you find that it has a lot of different fonts and what you can do is take these fonts and basically type of random text in your text editor. And screenshotted using different colors and different contrasts and very different fonts and you get synthetic data like that on the right. Synthetic data generation has been used most probably for computer vision tasks and less for other applications. Not that much for audio tasks as well.
Transfer learning
It turns out that there’s a technique called transfer learning which could apply in that setting to give your learning algorithm performance a huge boost. And the key idea is to take data from a totally different barely related tasks. But using a neural network there’s sometimes ways to use that data from a very different tasks to get your algorithm to do better on your application. Doesn’t apply to everything, but when it does it can be very powerful. The Process:
Pre-training:
Train a large neural network on a massive dataset of a different task (e.g., recognizing cats, dogs, etc.). This establishes basic image processing skills like detecting edges, corners, and shapes. Download pre-trained models from researchers or train your own.
Fine-tuning:
Take the pre-trained model’s parameters (except the final output layer) and use them as a starting point for your specific task (e.g., digit recognition). Choose one of two options: Option 1 (Freeze pre-trained layers): Only train the final output layer on your smaller dataset. This is suitable for very small datasets. Option 2 (Fine-tune all layers): Train all layers, but with the pre-trained weights as initialization. This works better with larger datasets.
Benefits:
Improved performance: Leverage the learning gained from the pre-trained model to achieve better results with limited data. Faster training: Fine-tuning requires less training time compared to training from scratch. Reduced computation: Utilize existing pre-trained models instead of training a massive network from scratch.
Limitations:
Input type consistency: Pre-trained models and fine-tuning data must have the same input type (e.g., images for image models, text for text models). Not a panacea: While effective, transfer learning doesn’t guarantee success on every task with minimal data.
Examples:
GPT-3, BERT, and ImageNet models demonstrate the power of pre-training and fine-tuning for diverse tasks.
Deployment