Bias and Variance
Evaluation Technique
Intro
J_train not being too high indicates this doesn’t have a high bias problem and J_cv not being much worse than J_train this indicates that it doesn’t have a high variance problem either.
Bias (underfitted)
If your learning algorithm has high bias, the key indicator will be if J train is high.
Variance (Overfitted)
the key indicator for high-variance will be if J_cv is much greater than J train does
Note
if you’re training a neural network, there are some applications where unfortunately you have high bias and high variance
One way to recognize that situation will be if J train is high, so you’re not doing that well on the training set, but even worse, the cross-validation error is again, even much larger than the training set. Meaning we fit the training set really well and we overfit in part of the input, and we don’t even fit the training data well, and we underfit the part of the input.
Regularisation
the value of Lambda is the regularization parameter that controls how much you trade-off keeping the parameters w small versus fitting the training data well.
Lambda very large
if Lambda were very large, then the algorithm is highly motivated to keep these parameters w very small and so you end up with w_1, w_2, really all of these parameters will be very close to zero.(d=0)
Lambda very small
setting Lambda equals zero you end up with that curve that overfits the data.
By trying out a large range of possible values for Lambda, fitting parameters using those different regularization parameters, and then evaluating the performance on the cross-validation set, you can then try to pick what is the best value for the regularization parameter.
Baseline level of performance
In order to judge if the training error is high, it turns out to be more useful to see if the training error is much higher than a human level of performance
-
how well humans can do on this task because humans are really good at understanding speech data, or processing images or understanding texts.
-
some competing algorithm, maybe a previous implementation that someone else has implemented or even a competitor’s algorithm
-guess based on prior experience
Learning curves
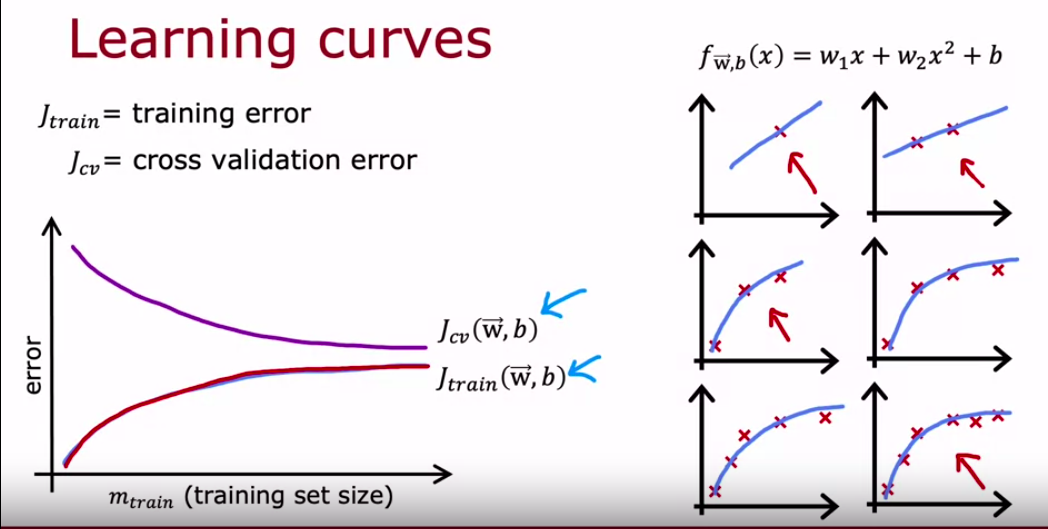
high bias
I know that we’re used to thinking that having more data is good, but if your algorithm has high bias, then if the only thing you do is throw more training data at it, that by itself will not ever let you bring down the error rate that much. fix a high bias problem
- adding additional features
- Adding polynomial features
- decreasing Lambda
high variance
If a learning algorithm suffers from high variance, then getting more training data is indeed likely to help. Because extrapolating to the right of this curve, you see that you can expect J cv to keep on coming down. fix a high variance problem:
- more training examples
- smaller set of features
- increasing Lambda
neural networks
Bias Variance tradeoff
large neural networks when trained on small / moderate sized datasets are low bias machines.
- first train your algorithm on your training set and then asked does it do well on the training set. So measure Jtrain and see if it is high and by high, I mean for example, relative to human level performance or some baseline level of performance and if it is not doing well then you have a high bias problem, high trainset error. And one way to reduce bias is to just use a bigger neural network and by bigger neural network, I mean either more hidden layers or more hidden units per layer. And you can then keep on going through this loop and make your neural network bigger and bigger until it does well on the training set.
- After it does well on the training set, so the answer to that question is yes. You then ask does it do well on the cross validation set? In other words, does it have high variance and if the answer is no, then you can conclude that the algorithm has high variance because it doesn’t want to train set does not do on the cross validation set.So that big gap in Jcv and Jtrain indicates you probably have a high variance problem, and if you have a high variance problem, then one way to try to fix it is to get more data. To get more data and go back and retrain the model and just double-check, do you just want the training set? If not, have a bigger network, or it does see if it does when the cross validation set and if not get more data. And if you can keep on going around and around and around this loop until eventually it does well in the cross validation set.
A large neural network with well-chosen regularization, well usually do as well or better than a smaller one. if you were to regularize this larger neural network appropriately, then this larger neural network usually will do at least as well or better than the smaller one. So long as the regularization has chosen appropriately.  TF lets you choose different values of lambda for different layers although for simplicity you can choose the same value of lambda for all the weights and all of the different layers as follows. And then this will allow you to implement regularization in your neural network.
TF lets you choose different values of lambda for different layers although for simplicity you can choose the same value of lambda for all the weights and all of the different layers as follows. And then this will allow you to implement regularization in your neural network.